
Artificial Intelligence is rapidly transforming the way machines interact with the world. From autonomous vehicles and industrial robots to smart cameras and drones, modern AI systems are becoming increasingly capable of understanding complex environments. However, recognizing an object is only one part of the challenge. Machines must also know exactly where that object is located and do so quickly enough to make real-time decisions.
This is where NVIDIA’s latest innovation, LocateAnything, is attracting significant attention. NVIDIA has introduced a new approach to object localization that can reportedly make object detection and localization up to 10 times faster than traditional methods used in Vision-Language Models (VLMs). While the concept may sound simple, its impact could be substantial across multiple industries.
For engineers, researchers, and technology enthusiasts, LocateAnything represents another step toward building AI systems that are not only intelligent but also fast, efficient, and practical for real-world deployment.
Why Object Localization Matters
When people think about computer vision, they often imagine AI identifying objects such as cars, people, traffic signs, or animals. While identification is important, practical applications require much more than simply recognizing an object.
Consider a warehouse robot. It may know that a box exists somewhere in front of it, but unless it knows the precise location of the box, it cannot pick it up. Similarly, a self-driving car must know the exact position of a pedestrian before making steering or braking decisions.
Object localization bridges the gap between recognition and action. It enables machines to interact intelligently with their surroundings by providing precise spatial information.
Key Benefits of Object Localization
- Determines the exact object position
- Helps robots interact with objects
- Enables safe navigation
- Supports autonomous decision-making
- Improves scene understanding
- Essential for real-time AI applications
Understanding Bounding Boxes
The most common way to localize objects is through bounding boxes. A bounding box is a rectangular outline that surrounds an object within an image or video frame.
When an AI model detects a car, it creates a rectangle around that car. The coordinates of the rectangle tell the system where the object begins and ends within the image.
Bounding boxes have been used for years because they are simple, computationally efficient, and effective for a wide range of applications. Almost every major object detection system relies on bounding boxes in some form.
Information Contained in a Bounding Box
• Object location
• Object size
• Object boundaries
• Position relative to other objects
• Input for tracking algorithms
• Input for robotic actions
Without accurate bounding boxes, many AI applications would struggle to function reliably.
The Evolution of Vision-Language Models
Recent years have seen explosive growth in Vision-Language Models. These systems combine visual understanding with natural language processing, allowing AI to understand both images and text simultaneously.
Instead of simply identifying objects, Vision-Language Models can answer questions about images, locate objects based on text prompts, and perform complex reasoning tasks involving visual content.
For example, a user can ask:
“Find the blue backpack next to the chair.”
The model must understand both the text instruction and the visual scene before identifying and locating the correct object.
Common Applications of Vision-Language Models
• Image question answering
• Visual search
• Robotics guidance
• Autonomous systems
• Content understanding
• Human-AI interaction
As these models become more powerful, localization speed becomes increasingly important.
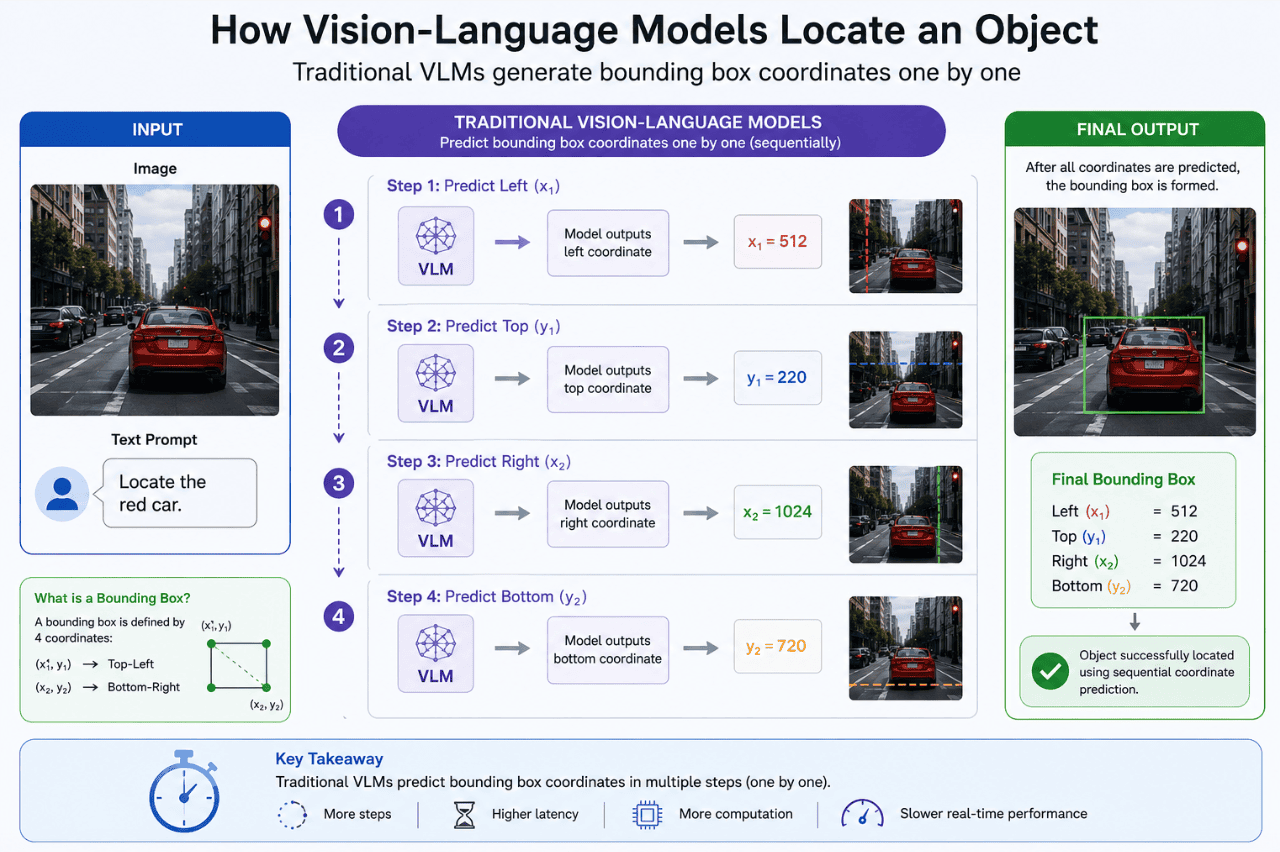
The Traditional Approach to Object Localization
Most Vision-Language Models generate bounding box coordinates sequentially. A bounding box is usually represented by four values:
• Left coordinate
• Top coordinate
• Right coordinate
• Bottom coordinate
Many existing systems predict these coordinates one at a time rather than generating the complete box simultaneously.
Although this approach has delivered good results for many years, it introduces computational overhead and latency.
Every additional prediction step requires processing time. As the number of objects increases, the total computation required can grow significantly.
Challenges of Sequential Prediction
• Multiple prediction steps
• Higher latency
• Increased computation
• Reduced efficiency
• Greater power consumption
• Potential error accumulation
These limitations become especially problematic in real-time applications.
The Need for Faster Localization
Speed is becoming one of the most important factors in modern AI systems. Many applications operate in environments where decisions must be made within milliseconds.
A warehouse robot cannot afford to wait several seconds before identifying and locating a package. Similarly, a self-driving car cannot delay decisions when approaching pedestrians or obstacles.
As AI systems process increasingly large volumes of visual data, traditional localization methods may become bottlenecks.
Researchers are therefore focusing on methods that can maintain high accuracy while significantly improving speed.
Why Speed Matters
• Faster decision-making
• Better user experience
• Improved safety
• Higher productivity
• Lower latency
• Enhanced scalability
This growing demand for efficiency led to the development of LocateAnything.
Introducing NVIDIA LocateAnything
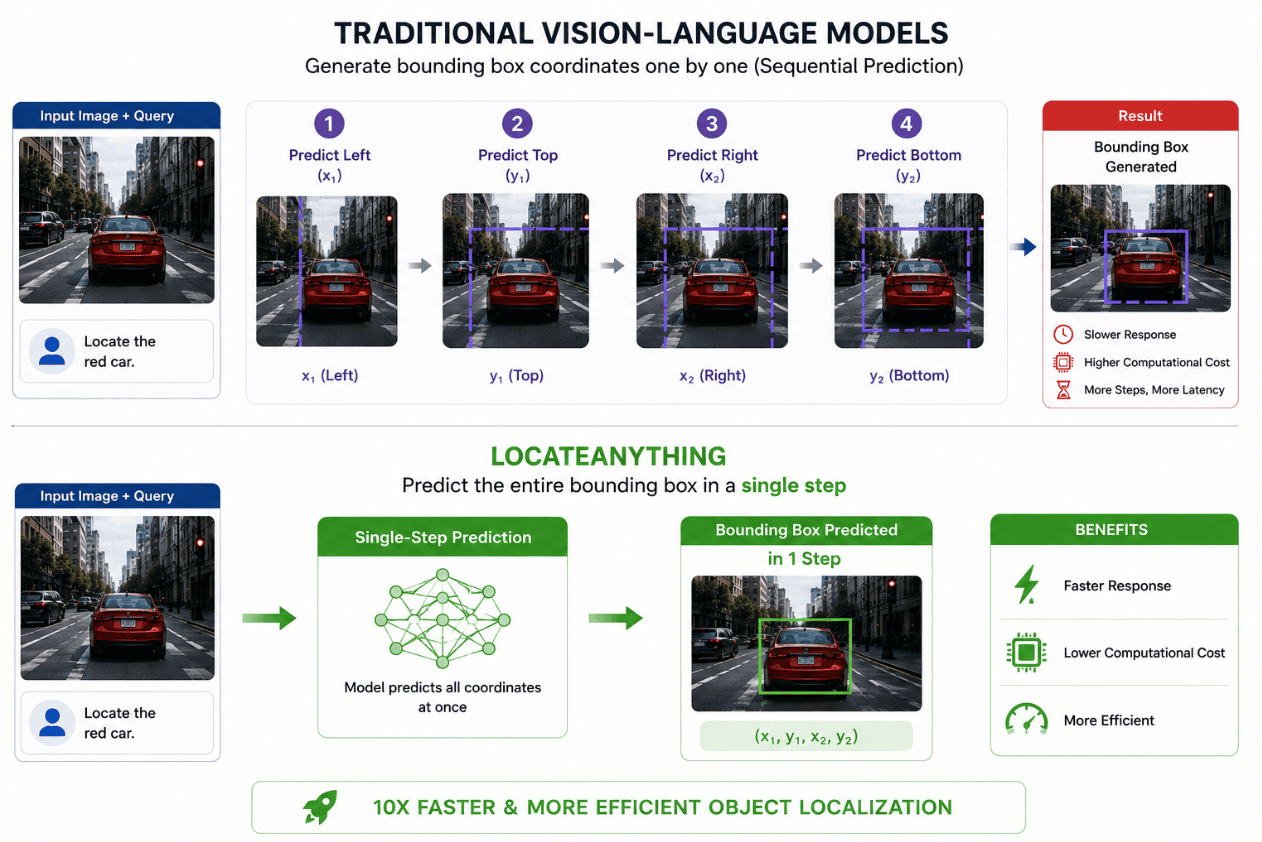
LocateAnything is NVIDIA’s new approach to object localization. Instead of predicting bounding box coordinates one by one, it predicts the entire bounding box in a single operation.
This architectural change eliminates many of the inefficiencies associated with traditional sequential methods.
Although the output remains the same—a bounding box around an object—the internal process becomes much faster and more efficient.
By reducing the number of prediction steps, LocateAnything significantly decreases inference time while maintaining localization quality.
Core Features of LocateAnything
• Single-step box prediction
• Reduced latency
• Faster inference
• Improved efficiency
• Better scalability
• Optimized for modern AI systems
This design enables AI systems to respond more quickly to changing environments.
How LocateAnything Achieves 10x Faster Performance
The key innovation lies in simultaneous prediction.
Traditional systems often generate bounding box coordinates sequentially. LocateAnything instead predicts the complete spatial representation at once.
This reduces the amount of computation required during inference and minimizes delays introduced by sequential processing.
As a result, the system spends less time generating outputs and more time performing useful work.
Performance Advantages
• Fewer computational steps
• Lower processing overhead
• Reduced latency
• Faster response times
• Improved throughput
• Better real-time performance
These improvements are especially valuable when processing large numbers of objects.
Impact on Robotics
Robotics is one of the industries that could benefit most from this innovation.
Modern robots depend heavily on computer vision to interact with their environments. Every movement a robot makes depends on accurate perception.
A robot must continuously identify tools, detect obstacles, locate components, and navigate safely through dynamic environments.
Faster localization enables robots to react more quickly and perform tasks with greater precision.
Robotics Applications
• Warehouse automation
• Manufacturing robots
• Service robots
• Agricultural robots
• Medical robots
• Logistics systems
The ability to localize objects faster can directly improve productivity and operational efficiency.
Impact on Autonomous Vehicles
Autonomous vehicles constantly analyze their surroundings using cameras, radar, LiDAR, and AI algorithms.
The vehicle must identify and locate cars, pedestrians, cyclists, traffic signs, and road markings in real time.
Every millisecond matters because delayed decisions can affect safety and vehicle performance.
LocateAnything can help reduce perception latency, allowing vehicles to respond faster to changing road conditions.
Autonomous Driving Benefits
• Faster obstacle detection
• Improved reaction time
• Better navigation decisions
• Enhanced safety
• Reduced processing delays
• More efficient perception systems
Although localization is only one component of autonomous driving, it plays a critical role.
Benefits for Industrial Automation
Factories increasingly rely on computer vision systems to improve efficiency and quality.
AI-powered cameras inspect products, detect defects, verify assembly processes, and guide robotic systems.
In high-speed manufacturing environments, even small improvements in processing speed can produce substantial productivity gains.
Faster localization allows factories to inspect more products while maintaining quality standards.
Industrial Use Cases
• Quality inspection
• Defect detection
• Product sorting
• Assembly verification
• Machine guidance
• Inventory management
This can lead to higher throughput and reduced operational costs.
Importance for Edge AI Devices
Many AI applications run on edge devices rather than cloud servers.
Examples include:
• Smart cameras
• Drones
• Mobile robots
• Embedded systems
• Industrial controllers
• IoT devices
These systems often have limited computing power and strict power consumption requirements.
Efficient localization techniques like LocateAnything can help deliver strong performance without requiring expensive hardware upgrades.
What Engineers Can Learn from LocateAnything
One of the most important lessons from LocateAnything is that innovation does not always require larger models.
For many years, AI progress focused on increasing model size. However, bigger models often come with higher costs and greater resource requirements.
Today, researchers are increasingly focused on architectural efficiency.
Sometimes a smarter design can provide larger benefits than simply adding more parameters.
Engineering Lessons
• Optimize before scaling
• Reduce unnecessary computations
• Focus on latency
• Improve deployment efficiency
• Design for real-world constraints
• Balance speed and accuracy
These principles apply across embedded systems, automotive software, robotics, and AI development.
Future Outlook
The demand for real-time AI will continue to increase over the coming years.
Future systems will need to process massive amounts of visual information while maintaining extremely low latency.
Industries such as robotics, transportation, healthcare, manufacturing, and smart infrastructure will benefit from faster and more efficient localization technologies.
LocateAnything demonstrates how innovative architectures can unlock significant performance improvements without sacrificing usability.
Areas Likely to Benefit
• Smart factories
• Autonomous vehicles
• Smart cities
• Healthcare robotics
• Logistics automation
• Consumer AI devices
As AI adoption grows, efficient perception systems will become increasingly important.
Conclusion
NVIDIA’s LocateAnything represents a significant advancement in computer vision and object localization. By predicting complete bounding boxes in a single step rather than generating coordinates sequentially, it dramatically improves localization speed and efficiency.
The technology addresses one of the most important challenges in modern AI systems: enabling machines to understand where objects are located quickly enough to take meaningful action. Whether in robotics, autonomous vehicles, industrial automation, drones, or embedded AI systems, faster localization can lead to better performance, improved safety, and more responsive decision-making.
The future of AI is not just about recognizing objects. It is about understanding the world, locating important information instantly, and acting on it in real time. LocateAnything moves the industry one step closer to achieving that goal.
Also, read:
- “Mother of All Deals”: How The EU–India Free Trade Agreement Can Reshape India’s Economic Future
- 10 Free ADAS Projects With Source Code And Documentation – Learn & Build Today
- 10 Tips To Maintain Battery For Long Life, Battery Maintainance
- 10 Tips To Save Electricity Bills, Save Money By Saving Electricity
- 100 (AI) Artificial Intelligence Applications In The Automotive Industry
- 100 + Electrical Engineering Projects For Students, Engineers
- 100+ C Programming Projects With Source Code, Coding Projects Ideas
- 100+ Indian Startups & What They Are Building


