When people first start learning Machine Learning, something feels surprising. You write just a few lines of Python code, press run, and suddenly your computer starts training a neural network that processes images, audio, or large datasets at very high speed. The code looks simple, readable, and almost beginner-friendly. Because of this experience, many learners assume Python must be a very fast language for heavy computation.
But the reality is different.
Python is actually slow for numerical computation. Yet AI frameworks built using Python run extremely fast. This contradiction exists because Python is not doing the heavy mathematical work. Instead, Python acts as a controller that calls powerful compiled programs written in C, C++, and CUDA. The performance you see comes from those lower-level languages running close to hardware speed.
This article explains what truly happens inside your program when you run a machine learning model.
1. The Biggest Misconception in Machine Learning
When people start learning Artificial Intelligence or Deep Learning, they experience something that feels almost magical.
They write code like:
model = NeuralNet()
output = model(input)They press run.
Suddenly:
- GPU fans spin loudly
- CPU usage jumps
- Training happens fast
- Huge datasets get processed quickly
The natural conclusion is:
Python must be an extremely powerful and fast language.
But here is the surprising truth:
Python itself is actually slow for heavy numerical computation.
Yes — slow.
So how can AI be fast if the language running it is slow? Because Python is not really running the AI.
Python is commanding it.
2. Python Is the Manager, Not the Worker
Imagine a construction site.
The site manager gives instructions:
“Lift that beam.”
“Pour the concrete.”
“Install the wiring.”
But the manager does not physically build the building.
Workers and machines do.
In Machine Learning:
| Role | Equivalent |
|---|---|
| Python | Manager |
| C++ | Workers |
| CUDA | Heavy machinery |
| GPU | Factory floor |
When you write:
loss.backward()Python does not calculate gradients.
Instead it says:
“Hey optimized C++ engine — compute gradients using GPU kernels.”
So the work is executed in compiled machine code at near-hardware speed.
3. Why Pure Python Would Be Too Slow
Let’s see a real example.
Matrix Multiplication in Pure Python
n = 300
A = [[1]*n for _ in range(n)]
B = [[1]*n for _ in range(n)]
C = [[0]*n for _ in range(n)]
for i in range(n):
for j in range(n):
for k in range(n):
C[i][j] += A[i][k] * B[k][j]This might take many seconds.
Why?
Because Python does this every step:
- Check variable type
- Find memory address
- Execute multiplication
- Handle dynamic objects
- Manage interpreter overhead
This happens millions of times.
Python interpreter overhead dominates computation.
Now Compare With NumPy
import numpy as np
A = np.ones((300,300))
B = np.ones((300,300))
C = A @ BRuns almost instantly.
Did Python suddenly become fast?
No.
Python did not multiply matrices.
It called a compiled library.
4. The Hidden Layers Beneath Your Code
Let’s follow one line:
y = torch.matmul(x, w)What actually happens:
- Python interpreter reads function call
- Python API forwards call to backend binding
- Control enters C++ tensor engine
- Backend selects CPU or GPU
- GPU kernel launches
- Thousands of threads compute results
- Memory copied back
- Python receives tensor object
You see one line.
The computer executes hundreds of steps.
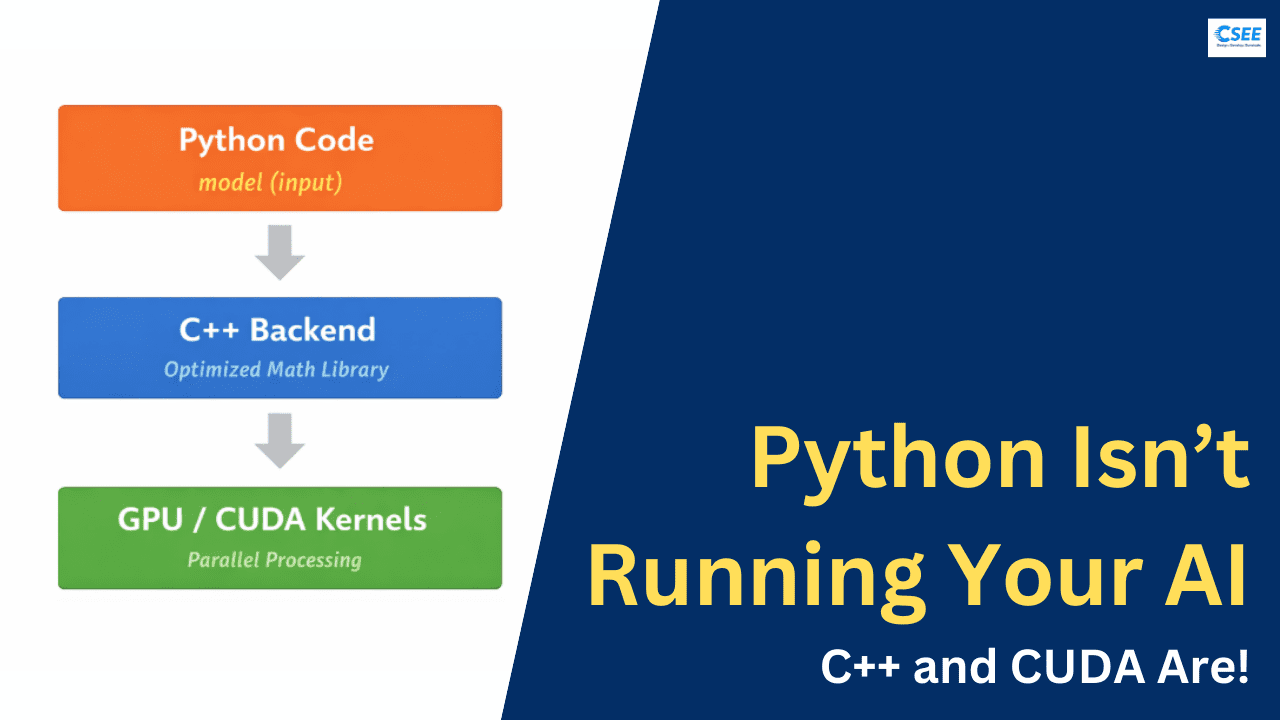
5. The Core Idea: Layered Architecture
Modern ML frameworks use a layered design.
Layer 1 — Python Frontend
Human-friendly interface
Layer 2 — C++ Backend
Tensor operations & memory management
Layer 3 — Math Libraries
BLAS, cuBLAS, cuDNN
Layer 4 — Hardware
CPU SIMD units / GPU cores
Why This Design Exists
Because humans need readability.
Computers need efficiency.
So we separate:
Expression vs Execution
Python expresses
C++ executes
When you run a deep learning operation, several layers activate in sequence.
Python first interprets your script and calls a function from a library. That library contains compiled binary modules. Control leaves the Python interpreter and enters a C++ backend. The backend decides whether to run the operation on CPU or GPU. If a GPU is available, CUDA kernels are launched. Thousands of GPU cores execute the operation simultaneously. After the computation finishes, the result is copied back and returned to Python.
From your perspective, it feels like a single function call. In reality, it is a full hardware execution pipeline.
6. Understanding CPU Optimization
CPUs do not calculate numbers one by one.
They use vector instructions.
Example:
Instead of:
1+1
2+2
3+3
4+4CPU can do:
[1,2,3,4] + [1,2,3,4]In one instruction.
This is called SIMD (Single Instruction Multiple Data).
Python loops cannot easily access this.
C++ compiled code can.
That alone makes massive speed differences.
7. Why GPU Changes Everything
Neural networks are mostly matrix multiplications. GPUs are built exactly for that.
CPU
- 8–32 cores
- Complex logic
- Sequential optimized
GPU
- 2000–20000 cores
- Simple logic
- Parallel optimized
When AI runs:
- Every neuron operation happens simultaneously.
- That’s why training speed increases 100×.
- Python cannot directly control GPU hardware.
- CUDA kernels written in C++ can.
8. Example: What Happens During Backpropagation
You write:
loss.backward()Inside:
- Graph traversal built in C++
- Gradient formulas executed
- Parallel matrix derivatives computed
- GPU tensor cores accelerate multiplication
- Results accumulated
Python only triggers the process.
9. Inside Popular Libraries
NumPy
- Python array wrapper
- Calls BLAS / LAPACK (C & Fortran)
PyTorch
- Python API
- C++ ATen tensor library
- CUDA kernels
TensorFlow
- Python interface
- Graph runtime in C++
OpenCV
- Python bindings
- Image algorithms in C++
All follow the same rule:
Python for usability
Native code for speed
10. Why Not Just Use C++ Directly?
Because research would slow down dramatically.
Compare writing a model.
Python
model = nn.Sequential(
nn.Linear(128,64),
nn.ReLU(),
nn.Linear(64,10)
)C++
- Hundreds of lines managing memory and tensors.
- AI evolves fast because Python allows rapid iteration.
- Researchers test ideas quickly.
- Engineers optimize backend separately.
11. The Binding Magic (How Python Talks to C++)
Python uses extension modules.
When you install PyTorch:
- You are not installing Python scripts.
- You are installing compiled binary libraries.
Python loads them using:
- CPython API
- pybind11
- C extensions
When calling a function:
Interpreter pauses → native code runs → interpreter resumes
This transition is extremely fast.
12. Automatic Differentiation Is Not Python Either
People think autograd is Python logic.
Actually:
- The graph engine is implemented in C++.
- Python just builds a graph description.
- Execution happens natively.
13. The Memory Layout Secret
Performance also depends on memory arrangement.
Computers are fast when data is contiguous.
Python lists store pointers:
[ptr][ptr][ptr][ptr]NumPy arrays store raw numbers:
[data][data][data][data]This allows cache-friendly access. That alone gives huge speed boost.
14. Why Loops Are Slow but Vectorization Is Fast
Bad:
for i in range(len(arr)):
arr[i] *= 2Good:
arr *= 2Second version runs in C backend.
15. Neural Network Training Step — Real Pipeline
When training:
for data, target in loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()Internally:
- Data copied to GPU
- Forward kernels execute
- Activation kernels execute
- Gradient kernels execute
- Parameter update kernels execute
Thousands of parallel launches per batch.
Python only controls flow.
16. Why This Matters for Learning AI
Beginners often think:
“I only need Python.”
But understanding system layers helps you:
- Debug performance
- Optimize training
- Understand GPU memory errors
- Write faster pipelines
Low-level languages provide precise control over hardware. They allow developers to optimize memory layout, cache usage, and CPU vector instructions. Modern processors contain SIMD instructions that can process multiple numbers in one operation. Python cannot directly access these efficiently, but C and C++ can.
They also integrate with GPU programming systems. GPUs are designed for parallel computation, where thousands of cores execute the same operation on different data. Neural networks rely heavily on matrix multiplication, which perfectly matches GPU architecture.
Because of this, AI frameworks delegate numerical operations to compiled backends.
17. The Real Mental Model
Instead of:
Python runs AI
Think:
Python describes a computation graph executed by optimized compiled kernels on specialized hardware.
You are writing instructions for a computing engine.
18. Future of AI Languages
New tools aim to reduce the gap:
- JAX compiles Python to XLA kernels
- Triton lets you write GPU kernels easier
- Mojo attempts Python syntax + C speed
But even these generate compiled code.
Because physics of hardware requires low-level execution.
19. Final Understanding
Machine learning feels simple because complexity is hidden.
Python is the user interface of a massive computing stack.
Underneath lies:
- Compilers
- Vector processors
- Parallel kernels
- Memory optimizations
- Hardware acceleration
So when you run a neural network, you are not executing a script.
You are orchestrating a high-performance computing system.
20. Architecture of Popular Libraries
NumPy provides arrays but internally uses BLAS and LAPACK libraries written in C and Fortran. PyTorch uses a C++ tensor engine and CUDA kernels for GPU acceleration. TensorFlow exposes Python functions but executes a compiled runtime graph engine. OpenCV image processing functions are implemented in C++ for speed while Python acts as a wrapper.
All these libraries follow the same architecture pattern: a user-friendly Python interface connected to a high-performance compiled core.
21. Why Python Is Still Used
If C++ is faster, why not write AI directly in C++? The answer is productivity. Python allows rapid experimentation. Researchers can modify model structures, test ideas, and debug easily. Writing the same logic in C++ would be complex and slow development dramatically.
The combination solves both problems. Python provides readability and flexibility. C++ provides speed. CUDA provides massive parallelism. Together they create an environment where complex AI systems can be both easy to write and extremely efficient to run.
22. The Real Mental Model
Instead of thinking “Python runs AI,” it is better to think:
- Python describes the computation.
- C++ performs the computation.
- CUDA accelerates the computation.
You write high-level instructions, and the system translates them into hardware-level execution.
23. Conclusion
Machine learning frameworks feel fast because they hide complexity behind a simple interface. The Python code you write is only the visible layer of a much deeper system. Underneath, optimized compiled programs and parallel hardware execute billions of operations per second.
Understanding this changes how you view programming in AI. You are not just writing scripts. You are controlling a high-performance computing engine using a human-friendly language. Python acts as the control center, while C++ and CUDA deliver the actual power.
That is why AI written in Python runs at near hardware speed.
Final Thought
You don’t run AI with Python.
You control AI with Python.
The real work happens in optimized native code operating near hardware limits.
That is why a few readable lines can train a system capable of understanding images, language, and speech.
- Python gives accessibility.
- C++ gives performance.
- CUDA gives scale.
Together they create modern artificial intelligence.
Thanks for reading.
Also, read:
- Highest-Paying Career Fields for EEE & ECE Engineers in 2026
- Embedded Engineer To AI Engineer Roadmap
- India’s First Private Orbital Rocket: How Skyroot Aerospace’s Vikram-1 Is Transforming the Future of India’s Space Industry
- Visually Explained MAAB / MAB Modeling Guidelines
- Visually Explained MISRA Guidelines
- Visually Explained Processor-In-The-Loop Testing, PiL Testing
- Visually Explained Software-In-The-Loop Testing, SiL Testing
- Visually Explained Model-In-Loop Testing, MiL Testing


