Artificial Intelligence has moved from research labs into daily engineering workflows, enterprises, startups, and even personal productivity tools. Names like ChatGPT, Gemini, and Perplexity have become synonymous with “AI that can answer anything.” But as adoption grows, a critical misunderstanding is also growing: people assume all AI systems work the same way.
They don’t.
This is where the distinction between LLM (Large Language Models) and RAG (Retrieval-Augmented Generation) becomes essential. Understanding this difference is no longer optional—it directly impacts accuracy, trust, scalability, and real-world usability, especially in professional and enterprise environments.
This article explains LLM vs RAG in depth, using simple language, real examples, engineering analogies, and clear architectural breakdowns.
1. What Is an LLM (Large Language Model)?
A Large Language Model (LLM) is a neural network trained on massive amounts of text data to predict the next word in a sequence. Over time, this simple objective results in surprisingly powerful capabilities: reasoning, summarization, explanation, translation, and code generation.
Popular LLM Examples
- ChatGPT
- Gemini
- Perplexity
- Claude
- LLaMA-based models
These models are trained on:
- Public websites
- Books
- Research papers
- Code repositories
- General internet data (up to a cutoff date)
Once trained, the model is frozen. It does not learn new facts unless retrained or fine-tuned.
2. What LLMs Are Extremely Good At

LLMs shine when the task involves general knowledge and reasoning.
Core strengths
- Explaining concepts clearly
- Reasoning through problems
- Writing structured content
- Summarizing information
- Generating code and pseudo-code
- Answering “why” and “how” questions
Example
Ask an LLM:
“What is CAN vs LIN in automotive networks?”
You’ll get:
- Clear explanation
- Protocol differences
- Speed comparison
- Use cases
This works because CAN and LIN are general, well-documented concepts present in training data.
3. The Fundamental Limitation of LLMs
LLMs do not have access to your private, internal, or recent data.
They cannot:
- Read your company documents
- Access your PDFs
- Know your meeting outcomes
- See internal wikis
- Recall decisions made yesterday
Critical example
Ask an LLM:
“What did our company decide in last Friday’s design review?”
The answer will be:
- A guess
- A generic response
- Or a disclaimer
Why?
Because that information never existed in its training data.
This limitation is not a bug.
It is a design constraint.
4. Why Guessing Is Dangerous in Real Systems
In casual use, a wrong answer is annoying.
In professional environments, it’s expensive or dangerous.
Industries affected
- Automotive
- Healthcare
- Finance
- Legal
- Aerospace
- Manufacturing
- Enterprise IT
Risks of LLM-only systems
- Hallucinated answers
- Confident but incorrect outputs
- Regulatory non-compliance
- Misinformed decisions
- Loss of trust
This is where RAG changes the game.
5. What Is RAG (Retrieval-Augmented Generation)?
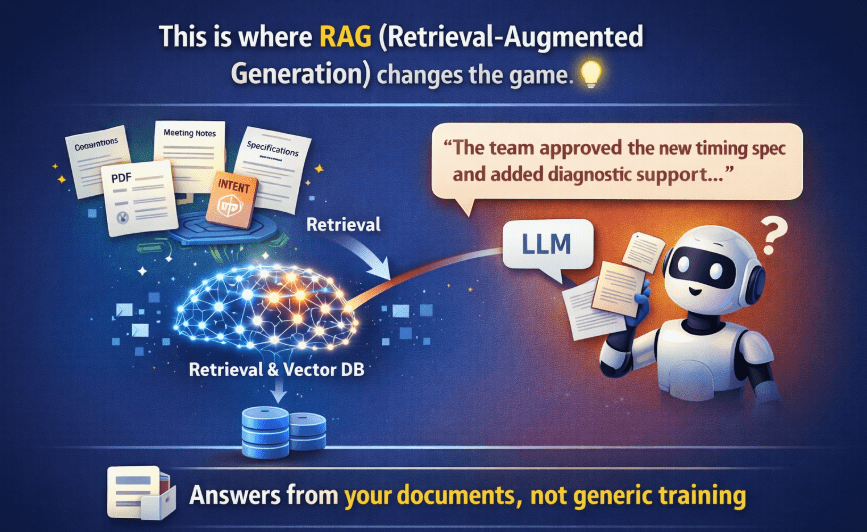
RAG = Retrieval + LLM Generation
Instead of forcing the LLM to rely only on memory, RAG allows it to look up information before answering.
Key idea
Don’t make the model guess.
Give it the right documents first.
6. How RAG Works (Conceptual Flow)
- User asks a question
- System searches relevant documents
- Relevant content is retrieved
- Retrieved content is injected into the prompt
- LLM generates an answer grounded in that data
Simple pipeline
User Question
↓
Retriever (Vector Search)
↓
Relevant Docs
↓
LLM
↓
Grounded Answer
7. What Data Can RAG Use?
With RAG, you can upload or connect:
- Meeting notes
- PDFs
- Specifications
- Requirement documents
- Internal wikis
- Design reviews
- Jira tickets
- Emails
- Logs
- Databases
- Web links
The LLM does not answer from training knowledge, but from your data.
8. Revisiting the Same Question With RAG
Without RAG (LLM-only)
“What did our company decide in last Friday’s design review?”
❌ Guess
❌ Generic response
❌ No real answer
With RAG
- Upload design review minutes
- System retrieves relevant section
- LLM summarizes actual decisions
✅ Accurate
✅ Verifiable
✅ Trustworthy
9. Key Difference in One Line
LLM answers from what it knows.
RAG answers from what you provide.
10. LLM vs RAG: Side-by-Side Comparison
| Aspect | LLM Only | RAG |
|---|---|---|
| Knowledge source | Training data | Training + your data |
| Private documents | ❌ No | ✅ Yes |
| Updated information | ❌ No | ✅ Yes |
| Hallucination risk | High | Lower |
| Enterprise-ready | Limited | Strong |
| Setup complexity | Low | Medium |
| Accuracy for internal queries | Poor | High |
11. Engineering Analogy (Systems Thinking)
LLM
Like an experienced engineer:
- Strong fundamentals
- Pattern recognition
- Reasoning skills
But no access to:
- Latest specs
- Meeting minutes
- Internal decisions
RAG
Same engineer with access to documentation:
- Opens PDFs
- Reads specs
- Checks meeting notes
- Confirms facts
Same brain.
Better inputs.
Better outputs.
12. RAG Is NOT Fine-Tuning
This is a common misconception.
Fine-tuning
- Changes model weights
- Expensive
- Slow
- Risky
- Hard to update
RAG
- No retraining
- Just retrieval at runtime
- Easy to update documents
- Scales well
RAG is inference-time knowledge injection, not training.
13. Typical RAG Architecture (Technical View)
Components
- Document loader
- Chunking system
- Embedding model
- Vector database
- Retriever
- LLM
Flow
Docs → Chunks → Embeddings → Vector DB
↓
User Query → Embedding → Similarity Search
↓
Relevant Chunks → Prompt → LLM → Answer
14. Why Vector Databases Are Used
Traditional databases search by keywords.
RAG uses semantic search.
Vector DB advantages
- Meaning-based retrieval
- Handles synonyms
- Works with natural language
- Scales to millions of documents
Examples:
- FAISS
- Pinecone
- Weaviate
- Milvus
15. Real-World Use Cases of RAG
1. Enterprise Knowledge Assistants
- HR policies
- IT documentation
- Onboarding guides
2. Engineering & Automotive
- ECU specifications
- AUTOSAR docs
- ISO standards
- Design reviews
3. Customer Support
- Product manuals
- FAQs
- Warranty documents
4. Healthcare
- Clinical guidelines
- Internal protocols
5. Legal & Compliance
- Contracts
- Regulations
- Policy interpretation
16. Why RAG Is Critical for Enterprises
Enterprises care about:
- Accuracy
- Traceability
- Compliance
- Data privacy
RAG provides:
- Answers backed by documents
- Source attribution
- Reduced hallucination
- Auditability
17. Limitations of RAG (Be Honest)
RAG is powerful—but not magic.
Challenges
- Poor document quality → poor answers
- Bad chunking → missing context
- Weak retrieval → irrelevant results
- Latency overhead
RAG systems need engineering discipline, not just AI hype.
18. Best Practices for RAG Systems
- Clean documents
- Proper chunk sizes
- Metadata tagging
- Hybrid search (keyword + vector)
- Prompt grounding
- Source citation
19. When LLM Alone Is Enough
Use LLM-only when:
- Topic is general
- Creativity is needed
- Accuracy is not mission-critical
- No private data involved
Examples:
- Learning concepts
- Writing posts
- Brainstorming ideas
20. When RAG Is Non-Negotiable
Use RAG when:
- Data is internal
- Decisions matter
- Accuracy is critical
- Compliance is required
Examples:
- “What does our spec say?”
- “What did we decide last week?”
- “Summarize this document”
21. The Future: LLM + RAG as the Default
The future is not:
- LLM vs RAG
The future is:
- LLM + RAG by default
LLMs provide intelligence.
RAG provides memory.
Together, they form usable AI systems.
22. Final Takeaway
LLMs make AI smart.
RAG makes AI trustworthy.
If you want:
- Explanations → LLM
- Decisions → RAG
- Enterprise AI → LLM + RAG
Understanding this difference is the line between AI demos and AI systems that actually work.
Thanks for reading.
Also, read:
- “Mother of All Deals”: How The EU–India Free Trade Agreement Can Reshape India’s Economic Future
- 10 Free ADAS Projects With Source Code And Documentation – Learn & Build Today
- 10 Tips To Maintain Battery For Long Life, Battery Maintainance
- 10 Tips To Save Electricity Bills, Save Money By Saving Electricity
- 100 (AI) Artificial Intelligence Applications In The Automotive Industry
- 100 + Electrical Engineering Projects For Students, Engineers
- 100+ C Programming Projects With Source Code, Coding Projects Ideas
- 100+ Indian Startups & What They Are Building